Ver código
library(tidyverse)
library(sf)
library(mapview)
OpenDataDay, Como descargar información desde el portal del INEGI.
En esta parte usaremos las siguientes librerías: tidyverse manipulación de datos, sf para lectura/manipulación de datos espaciales (vectoriales) mapview para una visualización sencilla. en caso de que no las tengas puedes usar el comando “install.packages(”acá el nombre de la librerías que vas a instalar”)” por ejemplo: install.packages(“sf”) y ejecutar la función.
Una vez instaladas, es necesario llamarlas.
library(tidyverse)
library(sf)
library(mapview)En el portal del INEGI, aparte de sus API’S como DENUE, banco de indicadores y el sistema de Ruteo (sakbe), podemos obtener directamente datos espaciales de México.
AlgunAs de ellAs lo haremos aplicados al Estado de Tlaxcala (por rápidez ya que es el más pequeño), puedes consultar acá las claves de la Entidad Catalogo Entidades y los datos que puedes obtener son: Área Geoestadística Estatal, Área Geoestadística Municipal, Localidad Geoestadística, Asentamientos o Vialidades
TIP
Los datos o los links de arriba regresan un archivo geojson, para que devuelva solo como formato de tabla borra la palabra geo del link
Para cada consulta es un link diferente o puede ser el mismo link pero se van agregando parámetros, acá te muestro como generar algunos de forma sencilla, pero puedes ver todos los ejemplos en el portal de servicios web en Guía para desarrolladores en el Catálogo Único de Claves Geoestadísticas.
Le información que puedes consultar está tanto en formato tabla(json) ó “espacial” (geojson). El primer ejemplo (y único) para Tabla (json) leeremos la información de población a nivel nacional.
Ojo que algunas veces ocupo las librerías de esta forma: “nombre::función”
Lo hago así ya que no quiero llamar a toda la librería únicamente a esa función. Acá la función viene de la librería jsonlite y la función “fromJSON” es la que lee ese tipo de archivos
pob_nal = jsonlite::fromJSON(
"https://gaia.inegi.org.mx/wscatgeo/v2/mgee/",
flatten = TRUE
)Al hacer esta consulta nos devuelve un objeto tipo lista que contiene 3 elementos: datos, metadatos, numReg
str(pob_nal)List of 3
$ datos :'data.frame': 32 obs. of 8 variables:
..$ cvegeo : chr [1:32] "01" "02" "03" "04" ...
..$ cve_ent : chr [1:32] "01" "02" "03" "04" ...
..$ nomgeo : chr [1:32] "Aguascalientes" "Baja California" "Baja California Sur" "Campeche" ...
..$ nom_abrev : chr [1:32] "Ags." "BC" "BCS" "Camp." ...
..$ pob_total : chr [1:32] "1425607" "3769020" "798447" "928363" ...
..$ pob_femenina : chr [1:32] "728924" "1868431" "392568" "471424" ...
..$ pob_masculina : chr [1:32] "696683" "1900589" "405879" "456939" ...
..$ total_viviendas_habitadas: chr [1:32] "386671" "1149563" "240660" "260824" ...
$ metadatos:List of 1
..$ Fuente_informacion_estadistica: chr "INEGI. Censo de Población y Vivienda, 2020"
$ numReg : int 32por default (en json) suelen venir todo en tipo texto, así que pasaremos a numérico las variables y sobreeescribiremos el objeto pob_nal y ya podemos ver los Estados son sus variables (por facilidad solo muestro 10)
pob_nal = pob_nal$datos %>%
mutate(across(c(pob_total:total_viviendas_habitadas),~as.numeric(.)))
pob_nal %>% head(10) cvegeo cve_ent nomgeo nom_abrev pob_total pob_femenina
1 01 01 Aguascalientes Ags. 1425607 728924
2 02 02 Baja California BC 3769020 1868431
3 03 03 Baja California Sur BCS 798447 392568
4 04 04 Campeche Camp. 928363 471424
5 05 05 Coahuila de Zaragoza Coah. 3146771 1583102
6 06 06 Colima Col. 731391 370769
7 07 07 Chiapas Chis. 5543828 2837881
8 08 08 Chihuahua Chih. 3741869 1888047
9 09 09 Ciudad de México CDMX 9209944 4805017
10 10 10 Durango Dgo. 1832650 927784
pob_masculina total_viviendas_habitadas
1 696683 386671
2 1900589 1149563
3 405879 240660
4 456939 260824
5 1563669 901249
6 360622 227050
7 2705947 1351630
8 1853822 1146915
9 4404927 2757433
10 904866 493989Usango gt podemos hacer una tabla sencilla y rápida con los primeros 10 registros.
pob_nal %>%
arrange(desc(total_viviendas_habitadas)) %>%
head(10) %>%
gt() %>%
fmt_number(
columns = c("pob_total":"total_viviendas_habitadas"),
decimals = 0,
use_seps = TRUE
) %>%
data_color(
columns = total_viviendas_habitadas,
method = "numeric",
palette = "viridis"
) %>%
cols_label_with(
fn = ~ html(str_to_title(gsub("_", "<br>", .x)))
)| Cvegeo | Cve Ent |
Nomgeo | Nom Abrev |
Pob Total |
Pob Femenina |
Pob Masculina |
Total Viviendas Habitadas |
|---|---|---|---|---|---|---|---|
| 15 | 15 | México | Mex. | 16,992,418 | 8,741,123 | 8,251,295 | 4,569,533 |
| 09 | 09 | Ciudad de México | CDMX | 9,209,944 | 4,805,017 | 4,404,927 | 2,757,433 |
| 30 | 30 | Veracruz de Ignacio de la Llave | Ver. | 8,062,579 | 4,190,805 | 3,871,774 | 2,391,262 |
| 14 | 14 | Jalisco | Jal. | 8,348,151 | 4,249,696 | 4,098,455 | 2,332,218 |
| 21 | 21 | Puebla | Pue. | 6,583,278 | 3,423,163 | 3,160,115 | 1,713,865 |
| 19 | 19 | Nuevo León | NL | 5,784,442 | 2,893,492 | 2,890,950 | 1,655,690 |
| 11 | 11 | Guanajuato | Gto. | 6,166,934 | 3,170,480 | 2,996,454 | 1,587,234 |
| 07 | 07 | Chiapas | Chis. | 5,543,828 | 2,837,881 | 2,705,947 | 1,351,630 |
| 16 | 16 | Michoacán de Ocampo | Mich. | 4,748,846 | 2,442,505 | 2,306,341 | 1,285,469 |
| 02 | 02 | Baja California | BC | 3,769,020 | 1,868,431 | 1,900,589 | 1,149,563 |
Como puedes ver solo leímos un link y fue sencillo de obtener, no necesitamos ningún token para poder leer la información, pero bueno ahora sí a leer datos espaciales (al fin!) ¿Recuerdas la Guía para desarrolladores? en el Catálogo Único de Claves Geoestadísticas cada información que indica, menciona que puedes obtener la información vectorial en formato geojson, puede ser ya sea a nivel nacional o información por Estado municipio, Ageb ,acá presentaremos algunos ejemplos
Para leer Una entidad en específico debemos armar un link. de la siguiente forma:
https://gaia.inegi.org.mx/wscatgeo/v2/geo/mgee/{cve_ent}*
Donde dice cve_ent es donde se debe reemplazar por un número del 1 al 32 para asignar los Estados, Algunos que me sé de memoria, 1 aguascalientes, el 15 Edo Mex, 09 CDMX, 32 Zacatecas etc.. Ojo que la clave del Estado debe ir a dos cifras, o sea si ponemos CDMX tendría que ser “09”, Puedes consultar las entidades acá CATÁLOGO DE ENTIDADES FEDERATIVAS y para hacernos la consulta sencilla lo dividimos en 2, el link_base y el estado que solo se lo pegamos. Haré el ejercicio con la clave 11 (Guanajuato)
Este es el link al que se hará la consulta:
link_base = "https://gaia.inegi.org.mx/wscatgeo/v2/geo/mgee/"
paste0(link_base,"29")[1] "https://gaia.inegi.org.mx/wscatgeo/v2/geo/mgee/29"y con la función st_read() (de la librería sf) leemos el link
# st_read viene de la librería sf
estado = st_read(
paste0(link_base,"11"),
quiet = TRUE
)¿Qué devuelve esta consulta?
Nos regresa un objeto espacial que contiene las variables: de Nombre del Estado, Población total, femenina, masculina y el total de viviendas habitadas (todo esto del último censo de población del 2020)
estado Simple feature collection with 1 feature and 8 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -102.097 ymin: 19.91275 xmax: -99.6713 ymax: 21.83942
Geodetic CRS: WGS 84
cvegeo cve_ent nomgeo nom_abrev pob_total pob_femenina pob_masculina
1 11 11 Guanajuato Gto. 6166934 3170480 2996454
total_viviendas_habitadas geometry
1 1587234 MULTIPOLYGON (((-101.3615 2...En R hay muchas formas de visualizar, plot, leaflet, con mapview puedes hacer la visualización dinámica.
mapview(estado)Recuerda que cuando leemos json lo lee todo como formato de texto.
Ahora intentemos con municipios, al hacer la misma opoeración ahora con el link de municipios y visualizarla a Cada alcaldía le asignó un color distinto, esto es porque está haciendo un “fill” por nombre y no por el valor de viviendas, puedes corroborar esto pasándolo a formato tabla
mun = st_read("https://gaia.inegi.org.mx/wscatgeo/v2/geo/mgem/09",quiet=TRUE)
mapview(mun,z="total_viviendas_habitadas")Formato tabla
mun %>% as_tibble()# A tibble: 16 × 10
cvegeo cve_ent cve_mun nomgeo cve_cab pob_total pob_femenina pob_masculina
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 09010 09 010 Álvaro O… ---- 759137 398130 361007
2 09016 09 016 Miguel H… ---- 414470 219003 195467
3 09005 09 005 Gustavo … ---- 1173351 609477 563874
4 09007 09 007 Iztapala… ---- 1835486 947835 887651
5 09015 09 015 Cuauhtém… ---- 545884 284933 260951
6 09017 09 017 Venustia… ---- 443704 233586 210118
7 09013 09 013 Xochimil… ---- 442178 226726 215452
8 09003 09 003 Coyoacán ---- 614447 325337 289110
9 09008 09 008 La Magda… ---- 247622 129335 118287
10 09009 09 009 Milpa Al… ---- 152685 78314 74371
11 09014 09 014 Benito J… ---- 434153 232032 202121
12 09011 09 011 Tláhuac ---- 392313 202123 190190
13 09006 09 006 Iztacalco ---- 404695 212343 192352
14 09002 09 002 Azcapotz… ---- 432205 227255 204950
15 09012 09 012 Tlalpan ---- 699928 365051 334877
16 09004 09 004 Cuajimal… ---- 217686 113537 104149
# ℹ 2 more variables: total_viviendas_habitadas <chr>,
# geometry <MULTIPOLYGON [°]>pasamos a numérico y sobreescribimos
mun = mun %>% mutate(across(c("pob_total":"total_viviendas_habitadas"),as.numeric))mapview(mun,z="total_viviendas_habitadas")El marco geoestadístico se actualiza cada diciembre aunque en su página indica que la próxima publicación será el 31 de agosto INEGI MG . Tal vez te preguntes ¿Bueno pero qué se actualiza? ¿Se agregan más estados? ¿Cuál debo ocupar? y la respuesta es “Depende” Los datos que leemos directamente del link son del último marco Geoestadístico, peero contiene la información del Censo del 2020 así que puedes encontrarte algunos municipios que no tengan información
#Guerrero
mun = st_read("https://gaia.inegi.org.mx/wscatgeo/v2/geo/mgem/12",quiet=TRUE)
mun = mun %>% mutate(across(c("pob_total":"total_viviendas_habitadas"),as.numeric))
mapview(mun,z="pob_total")En el mapa se muestran unas zonas en gris, que son municipios que no tiene información, por eso y no es que no tenga población, sino el próximo censo será en el 2030, así que probablemente surjan otros municipios, agebs rurales pasen a urbanos.. etc. Los siguientes Ejercicios los haremos de forma más rápida
solo por diversión, te mostraré a hacer un mapa vibariado, para esto debes tener la librería “bivariateLeaflet”
library(bivariateLeaflet)
ageb_tlaxcala = st_read("https://gaia.inegi.org.mx/wscatgeo/v2/geo/agebu/29") %>%
mutate(across(c("pob_total":"total_viviendas_habitadas"),as.numeric))Reading layer `29' from data source
`https://gaia.inegi.org.mx/wscatgeo/v2/geo/agebu/29' using driver `GeoJSON'
Simple feature collection with 675 features and 11 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -98.65882 ymin: 19.10507 xmax: -97.62544 ymax: 19.66969
Geodetic CRS: WGS 84mapa = create_bivariate_map(
data = ageb_tlaxcala,
var_1 = "pob_masculina", # Total population
var_2 = "pob_femenina" # Median household income
)
mapaRecuerda que vialidades es el único que no se puede a nivel Entidad así que debes integrar los dígitos del municipio
vialidades_tlaxcala = st_read("https://gaia.inegi.org.mx/wscatgeo/v2/geo/vialidades/29/001")Reading layer `001' from data source
`https://gaia.inegi.org.mx/wscatgeo/v2/geo/vialidades/29/001'
using driver `GeoJSON'
Simple feature collection with 768 features and 9 fields
Geometry type: MULTILINESTRING
Dimension: XY
Bounding box: xmin: -98.22655 ymin: 19.3385 xmax: -98.14951 ymax: 19.3799
Geodetic CRS: WGS 84mapview(vialidades_tlaxcala) En esta sección exploraremos algunas herramientas prácticas que amplían las posibilidades de tu análisis espacial. Algunos ejemplos calcular tiempos de desplazamiento, trazar rutas, y convertir texto en coordenadas (y viceversa).
Las isocronas delimitan el área alcanzable desde un punto en un tiempo determinado. En lugar de medir distancia en kilómetros (que ignora la infraestructura real) miden distancia en tiempo “real” de desplazamiento a través de vialidades. Ponemos “real” entre comillas ya que la movilidad va más allá de infraestructura, debe considerar la red de transporte, la configuración del terreno, la persona etc. aprovechando que tenemos los agebs, calculamos el centroide y sobre ese hacemos las isocronas (haremos solo 20 como ejemplo)
ageb_tlaxcala = st_read("https://gaia.inegi.org.mx/wscatgeo/v2/geo/agebu/29") %>%
head(20) %>%
mutate(across(c("pob_total":"total_viviendas_habitadas"),as.numeric)) %>%
st_centroid() Reading layer `29' from data source
`https://gaia.inegi.org.mx/wscatgeo/v2/geo/agebu/29' using driver `GeoJSON'
Simple feature collection with 675 features and 11 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -98.65882 ymin: 19.10507 xmax: -97.62544 ymax: 19.66969
Geodetic CRS: WGS 84Warning: st_centroid assumes attributes are constant over geometriesmapview(ageb_tlaxcala)Hay varias formas de generar isocronas, de forma rápida podemos usar ya sea con OSRM o MapBox Para ambas debes de delimitar.
Ejemplo OSRM con un solo punto (No necesitas ningún token), tenemos nuestro punto de partida y el área que podrías llegar en 5 y 15 mnts
punto_1 = ageb_tlaxcala[1,]
iso_1 = osrm::osrmIsochrone(
loc = punto_1, # Donde inicia
breaks = c(5,15), #Vector de tiempo
osrm.profile ="car" # como me voy a mover
)
mapview(iso_1,z="isomax")+
mapview(punto_1)con mapbox igual puedes crearlas, desde su api, puedes crear una cuenta de mapbox gratis (si tienes tu correo de universidad es super útil) , puedes crear tu cuenta acá MapBox
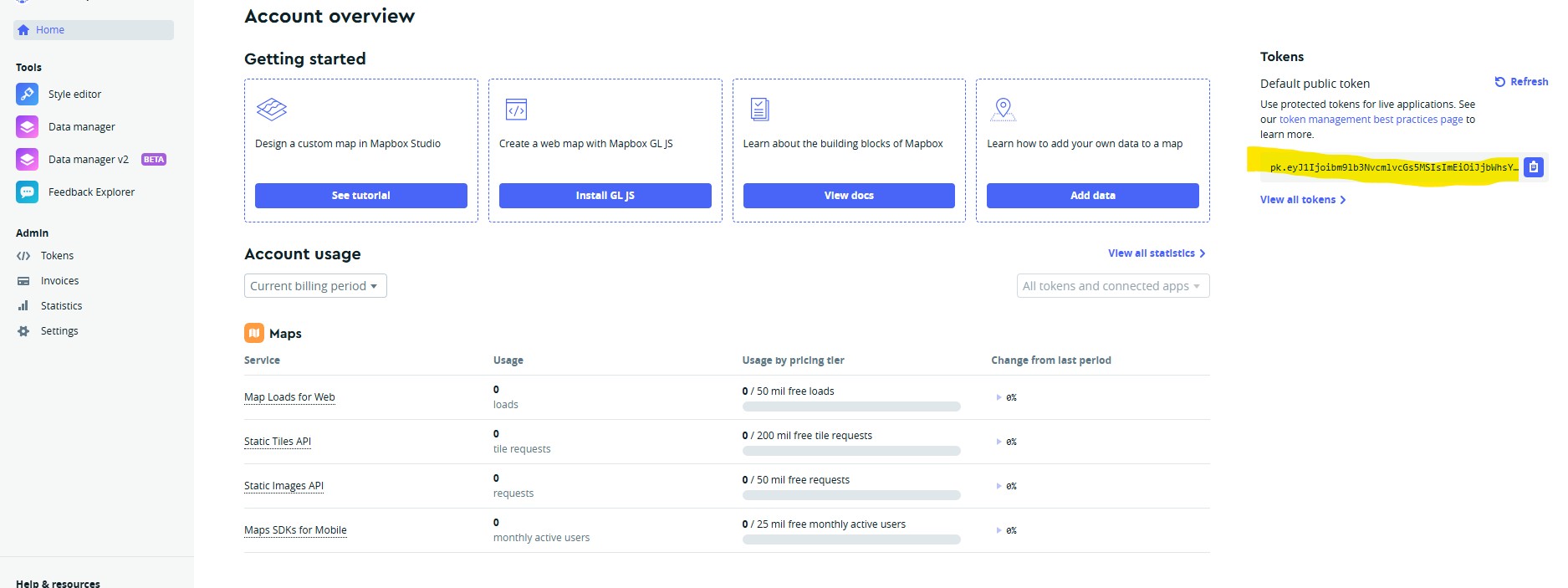
usa la función mb_acces_token para integrarlo como una variable de entorno.
El token de este ejemplo no es funcional, así que dentro d ela página puedes obtenerlo de forma gratuita, para guardarla como variable de entorno puedes ya sea hacer esta operación o con la librería use_this la función edit_r_environ() agregando el token a “MAPBOX_PUBLIC_TOKEN = …”
mapboxapi::mb_access_token(token = "pk.eyJ1Ijoi[TU_TOKEN_AQUÍ]",
install = TRUE)Ponemos ambas para que puedas compararlas. Hay más servicios y algoritmos, pero estos son dos muy comunes. (OSRM y MapBox)
library(mapboxapi)Usage of the Mapbox APIs is governed by the Mapbox Terms of Service.
Please visit https://www.mapbox.com/legal/tos/ for more information.iso_2 = mb_isochrone(location = punto_1,
profile = "driving",
time = c(5,15))
mapview(iso_1)+
mapview(iso_2,z="time")+
mapview(punto_1)El ruteo calcula rutas sobre la red vial entre dos puntos. Ya sea en Encuestas OD o en Distancias Cercanas es útil poder generar las rutas, acá si haremos al menos 10 rutas :) Seguimos con el ejemplo de los Agebs que tenemos como punto y lo separaré en dos objetos los 3 más poblados y veré cuáles son los agebs más cercanos a estas zonas, (hay una librería útil para esto nngeo)
install.packages(“nngeo”)
library(nngeo)
muy_poblados = ageb_tlaxcala %>% arrange(desc(pob_total)) %>%
head(5)
nn = st_nn(x = muy_poblados,
y =ageb_tlaxcala,
k = 5,
progress = FALSE)lon-lat pointsconectar = st_connect(x = muy_poblados,
y = ageb_tlaxcala,
ids = nn)Calculating nearest IDs
Calculating linesLos rojos son lo más poblados y la linea que los conecta son con el punto más cercano
library(leaflet)
leaflet() %>%
addProviderTiles(providers$CartoDB) %>%
addCircleMarkers(data=ageb_tlaxcala) %>%
addCircleMarkers(data=muy_poblados,color = "red",opacity = 1) %>%
addPolylines(data=conectar)ahora con ruteo, como primer paso es obtener lo más cercanos, con la misma librería y con un spatial join podemos lograrlo. POr facilidad solo me quedé con la variable de cvegeo de ambso objetos, la idea es luego filtrar sus coordenadas y hacer el ruteo, ORIGEN se repetirá 3 veces porque es la cantidad que puse de destinos en k y destino son los 3 más cercanos.
cercanos = st_join(muy_poblados %>% select(origen = cvegeo),
ageb_tlaxcala %>% select(destino=cvegeo),
join = st_nn,
k = 5,
progress = FALSE
)lon-lat pointscercanosSimple feature collection with 25 features and 2 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -98.20114 ymin: 19.33003 xmax: -98.16624 ymax: 19.35481
Geodetic CRS: WGS 84
First 10 features:
origen destino geometry
1 2900100010059 2900100010059 POINT (-98.16624 19.3465)
1.1 2900100010059 290010001003A POINT (-98.16624 19.3465)
1.2 2900100010059 2900100010063 POINT (-98.16624 19.3465)
1.3 2900100010059 2900200020075 POINT (-98.16624 19.3465)
1.4 2900100010059 2900100010044 POINT (-98.16624 19.3465)
2 2900100010063 2900100010063 POINT (-98.1713 19.35481)
2.1 2900100010063 2900100010059 POINT (-98.1713 19.35481)
2.2 2900100010063 2900100010082 POINT (-98.1713 19.35481)
2.3 2900100010063 2900200020075 POINT (-98.1713 19.35481)
2.4 2900100010063 2900100010044 POINT (-98.1713 19.35481)para el ruteo podemos realizarlo con una observación por una con un loop sencillo, pero antes ver si con uno funciona, en el ejercicio cada renglón es un “par” origen Destino, así que vamos a excluir los que su “origen es igual a su destino” ya que ocmo le pasamos todos lso agebs, lo incluye como el más cercano y agregamos una columna llamada “viaje” que es un identificador para el loop
base_ruta = cercanos %>%
filter(origen!=destino) %>%
mutate(viaje=1:n())
base_rutaSimple feature collection with 20 features and 3 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -98.20114 ymin: 19.33003 xmax: -98.16624 ymax: 19.35481
Geodetic CRS: WGS 84
First 10 features:
origen destino geometry viaje
1.1 2900100010059 290010001003A POINT (-98.16624 19.3465) 1
1.2 2900100010059 2900100010063 POINT (-98.16624 19.3465) 2
1.3 2900100010059 2900200020075 POINT (-98.16624 19.3465) 3
1.4 2900100010059 2900100010044 POINT (-98.16624 19.3465) 4
2.1 2900100010063 2900100010059 POINT (-98.1713 19.35481) 5
2.2 2900100010063 2900100010082 POINT (-98.1713 19.35481) 6
2.3 2900100010063 2900200020075 POINT (-98.1713 19.35481) 7
2.4 2900100010063 2900100010044 POINT (-98.1713 19.35481) 8
3.1 2900200010022 2900200050060 POINT (-98.19242 19.33003) 9
3.2 2900200010022 2900200040094 POINT (-98.19242 19.33003) 10Para calcular las rutas, primero definimos una función que toma el identificador de cada viaje, filtra el origen y destino en un solo paso con %in%, y obtiene la ruta con mb_optimized_route. Después, usamos map para aplicarla a todos los viajes y list_rbind para combinar los resultados en un solo dataframe. Esto es preferible a un for loop con rbind porque evita recrear el dataframe en cada iteración, lo que se vuelve lento con muchos viajes.
obtener_ruta = function(id_viaje) {
datos = base_ruta %>% filter(viaje == id_viaje)
ageb_tlaxcala %>%
filter(cvegeo %in% c(datos$origen, datos$destino)) %>%
mb_optimized_route(input_data = ., profile = "walking", output = "sf") %>%
pluck("route") %>%
mutate(id = id_viaje,
origen=datos$origen,
destino=datos$destino)
}
contenedor = map(base_ruta$viaje, obtener_ruta) %>%
list_rbind()¿Que nos regresa? una tabla con las geometrías, así que para pasarla un objketo espacial con la función “%>% sf::st_as_sf()”
contenedor geometry distance duration id origen
1 LINESTRING (-98.16594 19.34... 2.5408 30.49000 1 2900100010059
2 LINESTRING (-98.16594 19.34... 2.8488 34.18000 2 2900100010059
3 LINESTRING (-98.16594 19.34... 6.3346 76.01333 3 2900100010059
4 LINESTRING (-98.16594 19.34... 5.2446 62.93667 4 2900100010059
5 LINESTRING (-98.16594 19.34... 2.8488 34.18000 5 2900100010063
6 LINESTRING (-98.18093 19.35... 3.4284 41.14000 6 2900100010063
7 LINESTRING (-98.17122 19.35... 6.6402 79.68000 7 2900100010063
8 LINESTRING (-98.16437 19.36... 3.2508 39.00333 8 2900100010063
9 LINESTRING (-98.19237 19.32... 2.4080 28.89667 9 2900200010022
10 LINESTRING (-98.18931 19.33... 2.5332 30.39667 10 2900200010022
11 LINESTRING (-98.19237 19.32... 3.1114 37.33000 11 2900200010022
12 LINESTRING (-98.2043 19.333... 3.0690 36.82333 12 2900200010022
13 LINESTRING (-98.18931 19.33... 4.1118 49.34333 13 290020002008A
14 LINESTRING (-98.19757 19.33... 4.5226 54.25667 14 290020002008A
15 LINESTRING (-98.18246 19.35... 2.7976 33.57667 15 290020002008A
16 LINESTRING (-98.19237 19.32... 3.9726 47.66667 16 290020002008A
17 LINESTRING (-98.2043 19.333... 1.0868 13.04000 17 2900200050060
18 LINESTRING (-98.19757 19.33... 2.4288 29.13333 18 2900200050060
19 LINESTRING (-98.19237 19.32... 2.4080 28.89667 19 2900200050060
20 LINESTRING (-98.18931 19.33... 3.6252 43.49667 20 2900200050060
destino
1 290010001003A
2 2900100010063
3 2900200020075
4 2900100010044
5 2900100010059
6 2900100010082
7 2900200020075
8 2900100010044
9 2900200050060
10 2900200040094
11 2900200010037
12 2900200050056
13 2900200040094
14 2900200010037
15 2900200020075
16 2900200010022
17 2900200050056
18 2900200010037
19 2900200010022
20 2900200040094y visualizamos
espacial = contenedor %>%
sf::st_as_sf()
espacialSimple feature collection with 20 features and 5 fields
Geometry type: LINESTRING
Dimension: XY
Bounding box: xmin: -98.2043 ymin: 19.329 xmax: -98.15668 ymax: 19.36419
Geodetic CRS: WGS 84
First 10 features:
distance duration id origen destino
1 2.5408 30.49000 1 2900100010059 290010001003A
2 2.8488 34.18000 2 2900100010059 2900100010063
3 6.3346 76.01333 3 2900100010059 2900200020075
4 5.2446 62.93667 4 2900100010059 2900100010044
5 2.8488 34.18000 5 2900100010063 2900100010059
6 3.4284 41.14000 6 2900100010063 2900100010082
7 6.6402 79.68000 7 2900100010063 2900200020075
8 3.2508 39.00333 8 2900100010063 2900100010044
9 2.4080 28.89667 9 2900200010022 2900200050060
10 2.5332 30.39667 10 2900200010022 2900200040094
geometry
1 LINESTRING (-98.16594 19.34...
2 LINESTRING (-98.16594 19.34...
3 LINESTRING (-98.16594 19.34...
4 LINESTRING (-98.16594 19.34...
5 LINESTRING (-98.16594 19.34...
6 LINESTRING (-98.18093 19.35...
7 LINESTRING (-98.17122 19.35...
8 LINESTRING (-98.16437 19.36...
9 LINESTRING (-98.19237 19.32...
10 LINESTRING (-98.18931 19.33...leaflet() %>%
addProviderTiles(providers$CartoDB) %>%
addCircleMarkers(data=ageb_tlaxcala) %>%
addCircleMarkers(data=muy_poblados,color = "red",opacity = 1) %>%
addPolylines(data=conectar,color="black") %>%
addPolylines(data=espacial,color="green",opacity = 1)Convierte direcciones de texto en coordenadas geográficas. Es el primer paso para espacializar bases de datos administrativas: clínicas, escuelas, juzgados, centros de atención a violencia, etc.
Para este ejercicio vamos a usar la Plataforma Nacional de Datos Abiertos los datos de: Bibliotecas abiertas al público: Datos sobre la ubicación de las bibliotecas, nombre, dirección y servicios que se ofrecen.
bibliotecas = read.csv("https://repodatos.atdt.gob.mx/api_update/inah/bibliotecas_abiertas_publico/INAH_bibliotecas_abiertas_ok.csv",encoding = "utf8")
glimpse(bibliotecas)Rows: 71
Columns: 8
$ consecutivo <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ siglas <chr> "AGS", "BC", "BC - CDE", "BCS", "CAMP", "CHIS", "CHIS - …
$ estado <chr> "Aguascalientes", "Baja California", "Baja California", …
$ nombre <chr> "Biblioteca del Centro INAH Aguascalientes", "Biblioteca…
$ acceso <chr> "Público", "Público", "Público", "Restringido", "Público…
$ direccion <chr> "Calle Juan de Montoro No. 226, Zona Centro, C.P. 20000,…
$ perfil_acervo <chr> "Colecciones del INAH", "Biblioteca y archivos de Baja C…
$ servicios <chr> "sin dato", "Atención a usuario en sala y asesoría perso…El data set No contiene coordenadas pero sí contiene dirección así que con geocoding podemos obtener esas coordenadas. Dos opciones: * tidygeocoding * mapbox api
Ejemplo con tidygeocoding
Para no ver tantas columnas me quedaré con 2, consecutivo (como identificador y dirección) este es un ejemplo deuna dirección:
“Calle Juan de Montoro No. 226, Zona Centro, C.P. 20000, Aguascalientes, Aguascalientes.”
Tiene calle, me imagino que colonia, codigo postal, supongo que Municipio y Entidad. Para las funciones hay servicios gratuitos como OpenStretMap (OSM), arcgis y census (este último solo para Estados unidos) , en “method” se puede ajustar. Para este ejemplo le puse “arcgis”
library(tidygeocoder)
geo1 = bibliotecas %>%
select(consecutivo,nombre,direccion) %>%
mutate(direccion_completa = paste(direccion, "México")) %>%
geocode(address = "direccion_completa",
method="arcgis",
lat = "lat",
long = "lng")Passing 65 addresses to the ArcGIS single address geocoderQuery completed in: 23.6 secondsSi harás muchos te recomiendo madar por bloques, tipo primero dame 50, esperar unos segundos otros 50 .. etc en el ejemplo hizo las primeras 654
geo1 %>% glimpse()Rows: 71
Columns: 6
$ consecutivo <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, …
$ nombre <chr> "Biblioteca del Centro INAH Aguascalientes", "Bibli…
$ direccion <chr> "Calle Juan de Montoro No. 226, Zona Centro, C.P. 2…
$ direccion_completa <chr> "Calle Juan de Montoro No. 226, Zona Centro, C.P. 2…
$ lat <dbl> 21.88128, 32.66284, 31.86422, 24.14290, 19.84560, 1…
$ lng <dbl> -102.29291, -115.45858, -116.62992, -110.30807, -90…y magiaaa… ahora ya tenemos las coordenadas.
leaflet() %>%
addProviderTiles(providers$CartoDB) %>%
addCircleMarkers(data=geo1,label=~nombre)Assuming "lng" and "lat" are longitude and latitude, respectivelyVersión con MapBox
mapbox tiene una función llamada mb_batch_geocode que puedes pasarle un dataFrame, pero llega a “romperse” en cas ode que no reconozca una y no decirnos cuál es, así que pasar una por una (como en el ruteo) puede ser buena opción
Tip 2 si por alguna razón uno falla le agregamos un ‘posibly’, le pondremos null y saltará al otro es como una implementación del try_catch pero mucho más sencilla
geocodificar_uno_a_uno = function(dir) {
mb_geocode(
search_text = dir,
country = "MX",
language = "ES",
output = "sf"
)
}
geocodificar_safe = possibly(geocodificar_uno_a_uno, otherwise = NULL)
geo2 <- map(bibliotecas$direccion, geocodificar_safe) %>%
list_rbind()leaflet() %>%
addProviderTiles(providers$CartoDB) %>%
addCircleMarkers(data=geo1,label=~nombre,color="black") %>%
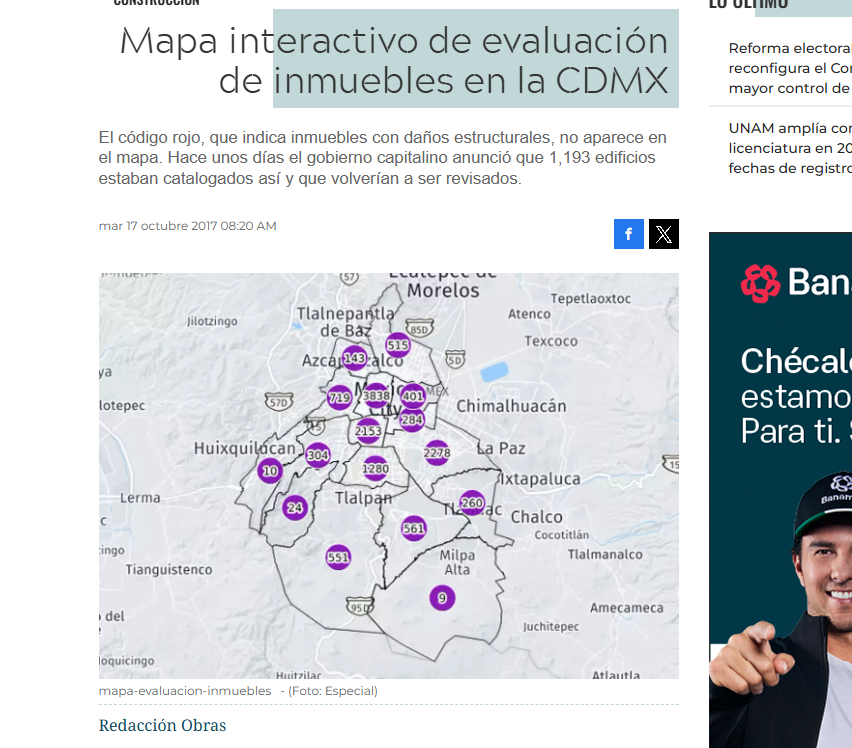
addCircleMarkers(data=geo2,color="red")Assuming "longitude" and "latitude" are longitude and latitude, respectivelyAssuming "lng" and "lat" are longitude and latitude, respectivelySeguramente te ha pasado que queremos extraer información de mapas ya sea históricos, algun mapa que te gustó y le tomaste una foto o hechos por otras personas pero no tenemos ni el archivo, ni conocemos a la persona o no pudimos contactarla, entonces con ayuda de modelos de lenguaje podemos apoyarnos en extraer la información. POr ejemplo acá hay un mapa (Puedes tomarle foto)
Para usar los modelos de lenguaje en R existen distintas librerías, una que me gusta a mí se llama ellmer , pero antes de iniciar para ocupar modelos de lenguaje tenemos 2 Opciones:
Debes guardar las variables en una variable de entorno (puedes hacerlo de forma sencilla con la librería usethis con la función usethis::edit_r_environ()) , se abrirá una ventana y ahí podrás asignar tus variables, una vez que las tengas, las guardarás, cerrarás la pestañas y reiniciarás “R” Ya sea asi usaste algún llm de github o gemini usaremos la palabra chat, (para hacernos la vida un poco facil en este ejercicio ) les llamaremos m1 y m2
library(ellmer)
ellmer::models_google_gemini() id cached_input input output
1 deep-research-pro-preview-12-2025 NA NA NA
2 gemini-2.0-flash 0.02500 0.100 0.4
3 gemini-2.0-flash-001 0.02500 0.100 0.4
4 gemini-2.0-flash-lite 0.01875 0.075 0.3
5 gemini-2.0-flash-lite-001 NA NA NA
6 gemini-2.5-computer-use-preview-10-2025 NA NA NA
7 gemini-2.5-flash 0.07500 0.300 2.5
8 gemini-2.5-flash-image NA NA NA
9 gemini-2.5-flash-lite 0.02500 0.100 0.4
10 gemini-2.5-flash-lite-preview-09-2025 0.02500 0.100 0.4
11 gemini-2.5-flash-preview-tts 0.03750 0.150 0.6
12 gemini-2.5-pro 0.31250 1.250 10.0
13 gemini-2.5-pro-preview-tts 0.31250 1.250 10.0
14 gemini-3-flash-preview NA NA NA
15 gemini-3-pro-image-preview NA NA NA
16 gemini-3-pro-preview NA NA NA
17 gemini-3.1-flash-image-preview NA NA NA
18 gemini-3.1-flash-lite-preview NA NA NA
19 gemini-3.1-pro-preview NA NA NA
20 gemini-3.1-pro-preview-customtools NA NA NA
21 gemini-flash-latest 0.07500 0.300 2.5
22 gemini-flash-lite-latest 0.02500 0.100 0.4
23 gemini-pro-latest NA NA NA
24 gemini-robotics-er-1.5-preview NA NA NA
25 gemma-3-12b-it NA NA NA
26 gemma-3-1b-it NA NA NA
27 gemma-3-27b-it NA NA NA
28 gemma-3-4b-it NA NA NA
29 gemma-3n-e2b-it NA NA NA
30 gemma-3n-e4b-it NA NA NA
31 nano-banana-pro-preview NA NA NAm2 = chat_google_gemini()Using model = "gemini-2.5-flash".Una vez que tenemos nuestro modelo podemos verificar si puede “respondernos”
m2$chat("CUentame un chiste breve sobre datos abiertos ")¡Aquí tienes uno!
¿Cuál es el chiste de los datos abiertos?
Que están... **¡tan abiertos que a veces necesitas un mapa del tesoro para
encontrarlos!**m2$chat("se breve, ¿Sabes que esel OpenDataDay?")Sí, es un evento anual que celebra y promueve el uso y el impacto de los datos
abiertos a nivel mundial.Ahora sí el vamos a extraer los valores de la imagen.
1.- Necesitamos ya se auna foto/archivo 2.- Una tabla para asignar las variabels 3.- el chat
La imagen del mapa la guardé en un objeto llamado “i2.png”
foto = google_upload(path = "imagen/i2.png")
m2 = chat_google_gemini(system_prompt = "Tu objetivo es ayudarme a extraer los valores")Using model = "gemini-2.5-flash".type_datos = type_object(
id = type_string("Genera un id para cada registro del registro que inicie con 'p_1','p_2','p_3' hasta el limite de registros"),
valor = type_integer("cantidad de valores que observas registrados"),
lat=type_number("integra la latitud del punto valor, la ubicación se encuentra en CDMX Mexico"),
lng=type_number("integra la longitud del punto valor, la ubicación se encuentra en CDMX Mexico")
)
type_final = type_array(items = type_datos)resultado = m2$chat_structured(
foto,
type = type_final,
"Extrae todos las cantidades visibles en el mapa así como sus coordenadas"
)resultado# A tibble: 18 × 4
id valor lat lng
<chr> <int> <dbl> <dbl>
1 p_1 850 19.5 -99.2
2 p_2 515 19.5 -99.2
3 p_3 143 19.5 -99.1
4 p_4 719 19.5 -99.2
5 p_5 3838 19.4 -99.2
6 p_6 401 19.4 -99.1
7 p_7 284 19.4 -99.1
8 p_8 2153 19.4 -99.2
9 p_9 304 19.4 -99.3
10 p_10 10 19.3 -99.3
11 p_11 1280 19.3 -99.2
12 p_12 24 19.3 -99.2
13 p_13 551 19.2 -99.2
14 p_14 950 19.2 -99.2
15 p_15 9 19.2 -99.0
16 p_16 260 19.3 -99.0
17 p_17 561 19.2 -99.1
18 p_18 2278 19.4 -99 leaflet() %>%
addProviderTiles(providers$OpenStreetMap) %>%
addCircleMarkers(data=resultado,label = ~scales::comma(valor))Assuming "lng" and "lat" are longitude and latitude, respectively“Peor es nada” aunque el prompt fue muy ambiguo fue un poco “útil” ¿Qué podemos pasarle para mejorar? el límite de la entidad, un prompt mucho mejor, más detallado etc.. pero como primer acercamiento es útil.
¿Te hapasado que quieres extraer información de un texto? estructurarlo, extraer personasjes incluso asignarles características, bueno nos apoyaremos del modelo de lenguaje, Durante el OpenDataDay Hicimos Este ejercicio

La idea es extraer el texto así como tratar de inferir el género de la persona y las coordenadas de donde viene. el documento lo puedes descargar de acá Documento
(por alguna razón le puse de nombre MapBox (1).pdf)
archivo = google_upload(path = "imagen/token mapbox (1).pdf")
m2 = chat_google_gemini(system_prompt = "Identifica los nombres en español, asigna el género de la persona, así como sus coordenadas del Archivo")Using model = "gemini-2.5-flash".type_datos = type_object(
nombre = type_string("Nombre en español de la persona",required = FALSE),
genero = type_string("Genero que identifiques asociado al nombre",required = FALSE),
origen=type_string("Indica de donde proviene la persona",required = TRUE),
lat=type_number("Obten las latitud del origen de la persona",required = TRUE),
lng=type_number("Obten la longitud del origen de la persona",required = TRUE)
)
type_final = type_array(items = type_datos)Ahor ya que tenemos la estructura así como las variables que nos interesan podemos llamar al modelo nuevamente, acá usamos una función llamada “requiered” esta es importante ya que si le pones TRUE el modelo se “esforzará” por devolverte algo, para los que no lo tienen puede dejarlos en NULL en caso de que no identifique la información
resultado_final = m2$chat_structured(
archivo,
type = type_final,
"Extrae nombres, genero, origen y sus coordenadas del archivo"
)nota improtante la clase de valor debe estar asociada al tipo, por ejemplo type_string son palabras, type number números
resultado_final# A tibble: 6 × 5
nombre genero origen lat lng
<chr> <chr> <chr> <dbl> <dbl>
1 Noé Masculino Ecatepec 19.6 -99.1
2 Juan Javier Masculino Portales CDMX 19.4 -99.1
3 Yoselin Femenino Ciudad Juárez, Chihuahua 31.7 -106.
4 Javier Masculino Narvarte 19.4 -99.2
5 Ana Femenino Cancún 21.2 -86.8
6 Vale Femenino Yucatán 21.0 -89.6La ventaja de modelos de lenguaje para extraewr información es que podemos ponerles solo una palabra, un sitio y puede asignarle la coordenada.
leaflet() %>%
addProviderTiles(providers$OpenStreetMap) %>%
addCircleMarkers(data = resultado_final,label = ~nombre)Assuming "lng" and "lat" are longitude and latitude, respectivelyPerdón la demora en compartir las notas, espero te sea de utilidad.
Dudas,Quejas,retroalimentación, Reclamos y chistes, siempre feliz de escuchar.
Contactos:
Noé Osorio: ecostat.nog@gmail.com / X
Uriel Mendoza: urielmendozacastillo@gmail.com